用于异常检测的机器学习Envelope模型
 |
 |
William Conner - INFICON 应用程序总监
背景
时间序列异常检测 (即通过在过程中检查数据与时间的关系来检测错误数据) 需要使用多种先进的算法来发现数据中微小而重要的变化,但不提高假阳性率。为了满足对自动异常检测的不断增长的需求,INFICON 专攻久经考验的统计envelope分析与机器学习相结合的方法,做到以更少的用户配置实现更精确的故障检测。
为什么使用envelope模型?
envelope模型最适用于用户解读。与只能确定是否存在故障的模型不同,计算时间序列envelope的模型能够绘制时间序列数据的变化并显示故障发生的时间。
机器学习时间序列envelope模型
统计envelope模型使用历史数据来确定每个步骤中的每个变量的预期变化以及所有过程中的每个时间点的预期变化。该模型根据所确定按时间变化变量的"完美"路径和所观测到的数据变化来计算上限和下限 (图 1)。
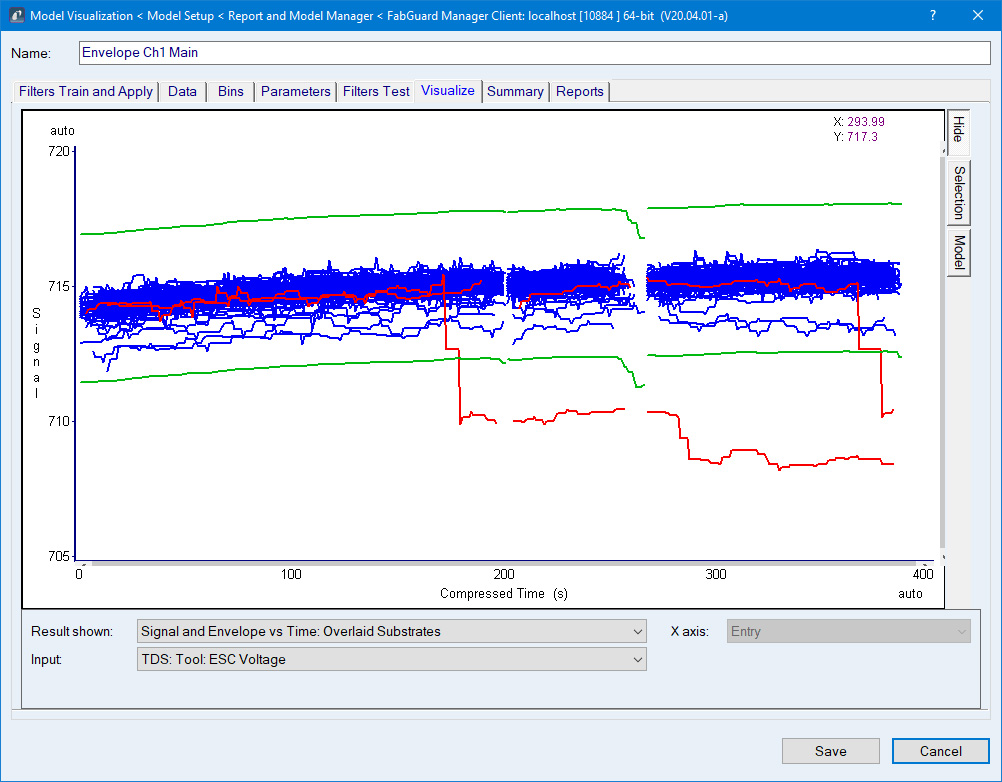
图 1:一个配方中三个步骤的一个参数的时间序列数据。蓝色表示训练数据,绿色表示确定的envelope线,红色表示识别出的异常数据。
模型的机器学习组件自动检查数据并修改算法,以优化故障检测。模型会自动执行:
- 在步骤转换中只使用新数据,减少由于数据采样和内部工具更新而导致的上一步"入侵"的影响
- 确定最佳数据归一化
- 从数据中去除噪声成分,如振荡、比特噪声和最小有意义信号
- 通过考虑相邻点的envelope限值来减少假阳性
为了计算每个参数最适用的时间路径,模型对每个参数进行分类。类别包括:
- 设定值
- 受控 (如温度)
- 执行器 (如加热器电流)
- 不受控绝对值 (如DC偏差)
- 不受控相对值 (如光发射端点)
新过程的持续学习和培训
建模基础设施学习在每个工具中每个单元上运行的过程,同时生成新模型、执行自动培训并跟踪故障。随着新配方的开发和新产品的引入,用户不再需要决定哪些过程需要监控,也不需要记得更新分析。
模型以持续学习为设计目的,并接受用户输入的检测到的故障和遗漏的故障,以持续调整envelope线计算结果。如果随后发现故障,模型将比较外部信息和内部发现结果,并调整自身以适应以后的异常检测。
贝塔测试正在进行
INFICON 目前正与几个客户合作,在生产环境中对时间序列异常检测模型进行贝塔测试,计划在 2021 年第一季度上市销售。