異常検出のための機械学習包絡モデル
 |
 |
ウィリアム・コナー - ウィリアム・コナー – アプリケーション
バックグラウンド
時系列異常検出、すなわちプロセス中にデータと時間の関係を分析することにより異常データを検出する場合、誤検出率を上昇させることなくデータ内の小さいながらも重要な変化を検出するには、複合的な先進アルゴリズムの利用が必要です。自動異常検出への高まるニーズに対応するため、INFICONは実績のある統計的包絡分析と機械学習法を統合することに焦点を当て、ユーザー構成を少なくした、より精度の高い不良検出を実現します。
なぜ包絡モデルなのか?
包絡モデルはユーザー解釈に最適です。異常の有無しか特定できないモデルとは違って、時系列包絡を計算するモデルは時系列データ内の変化をグラフで表し、異常がいつ発生したかを示すことができます。
機械学習時系列包絡モデル
統計包絡モデルは、各プロセス内の各変数、および全プロセスにおける各時点に関して予測される変化を特定するために、過去のデータを使用します。このモデルは、時間における変数の「完全な」パスおよびデータ内で観察された変化として特定されるものに基づいて、上限と下限を算出します(図1)。
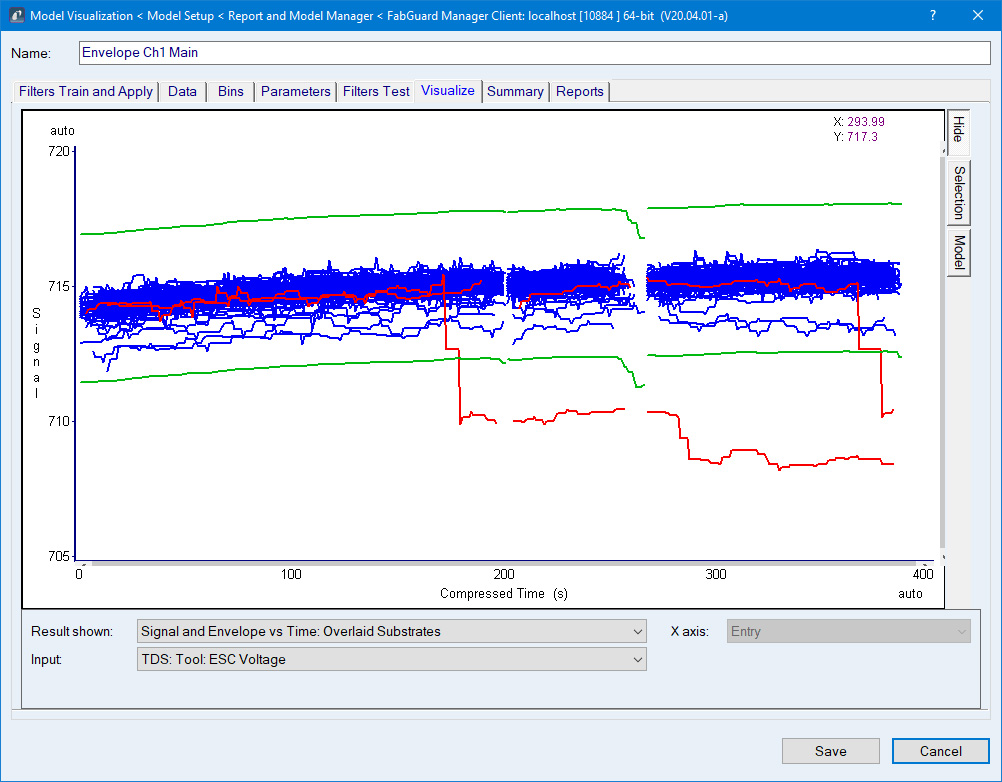
図1:1つのパラメーターセットにおける3つのプロセスステップでの単一変数に関する時系列データ。学習データは青色、特定された包絡は緑色、識別された異常データは赤色で示されています。
モデルの機械学習コンポーネントは自動的にデータを分析し、不良検出を最適化するためにアルゴリズムを変更します。モデルは自動的に以下を行います:
- ステップ移行時に新しいデータのみを使用し、データ収集と内部ツール更新による前ステップの「侵害」の影響を減らす
- 最良のデータ正規化を判断する
- 振動、少量ノイズ、最小有意信号などのノイズ成分をデータから取り除く
- 隣接点の包絡限界を考慮することにより、誤検出を低減する
各パラメーターに対する最適な時間パスを算出するために、モデルは各パラメーターを分類します。分類項目:
- 設定値
- 制御される値(温度など)
- アクチュエーター(ヒーター電流など)
- 制御されない絶対値(DCバイアスなど)
- 制御されない相対値(発光終点など)
新しいプロセスの持続的な学習とトレーニング
モデル化インフラストラクチャは全ツールの全チャンバーで実行されているプロセスを学習し、新しいモデルの生成、自動トレーニングの実行、不良の追跡を行います。ユーザーはどのプロセスを監視する必要があるかを決めなくてもよく、また新しいパラメーターセットが開発されたときや新しい製品が工場に導入されたたときに解析を更新する必要もありません。
モデルは継続的な学習を実行するように設計されており、検出された不良および見逃された不良についてのユーザー入力を受け取り、計算された包絡を絶えず調整します。不良が遅れて識別された場合、モデルは外部情報を内部調査結果と比較し、その後の異常検出のために自らを調整します。
現在ベータテストを実施中
INFICONは現在複数の顧客と提携して、製造環境において時系列不良検出モデルのベータテストを実施しており、2021年の第1四半期での販売を予定しています。